



Citizen science video games are designed primarily for users already inclined to contribute to science, which severely limits their accessibility for an estimated community of 3 billion gamers worldwide.
Citizen science video games are designed primarily for users already inclined to contribute to science, which severely limits their accessibility for an estimated community of 3 billion gamers worldwide.
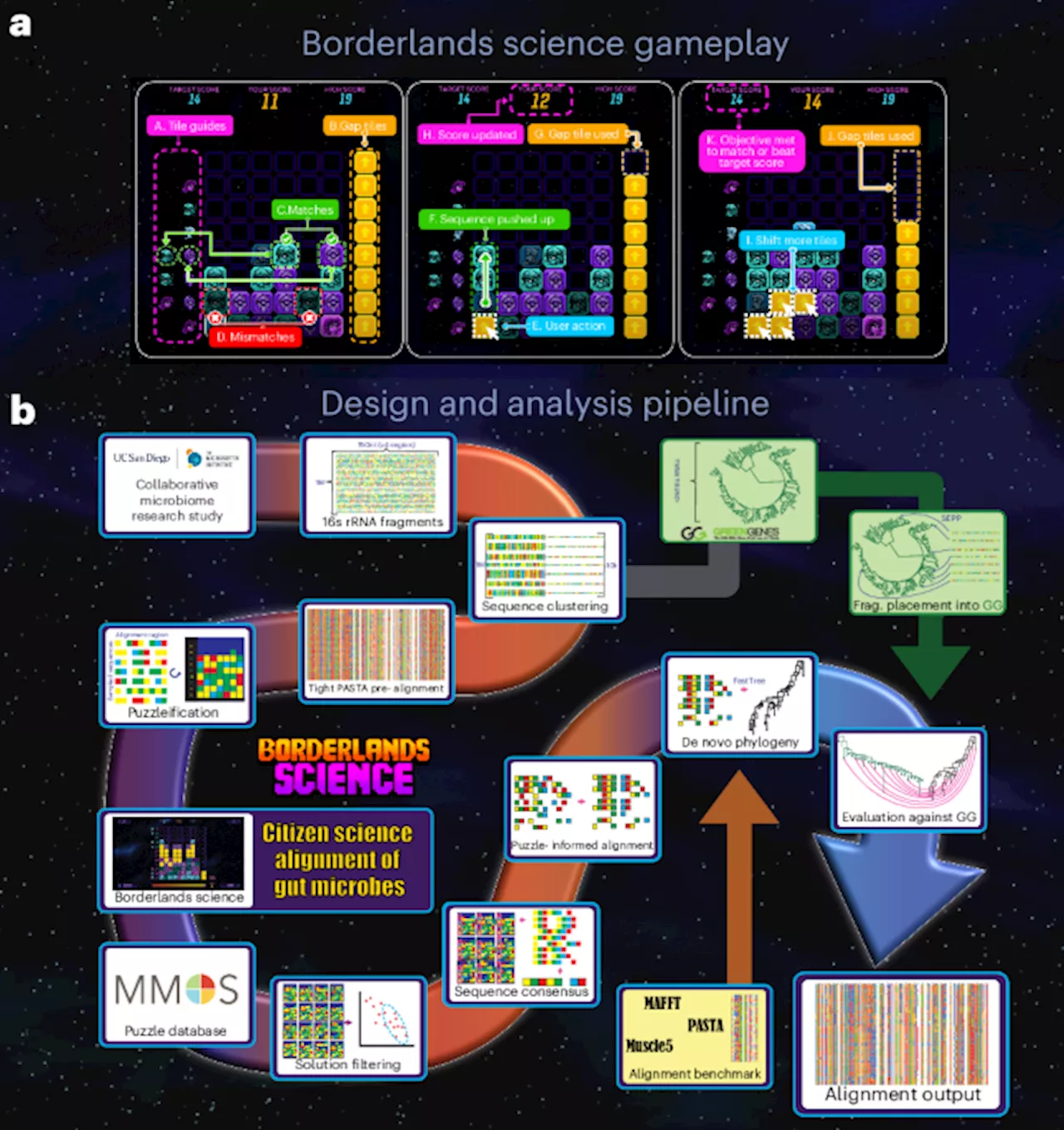
We created), a citizen science activity that is seamlessly integrated within a popular commercial video game played by tens of millions of gamers. This integration is facilitated by a novel game-first design of citizen science games, in which the game design aspect has the highest priority, and a suitable task is then mapped to the game design.crowdsources a multiple alignment task of 1 million 16S ribosomal RNA sequences obtained from human microbiome studies. Since its initial release on 7 April 2020, over 4 million players have solved more than 135 million science puzzles, a task unsolvable by a single individual. Leveraging these results, we show that our multiple sequence alignment simultaneously improves microbial phylogeny estimations and UniFrac effect sizes compared to state-of-the-art computational methods. This achievement demonstrates that hyper-gamified scientific tasks attract massive crowds of contributors and offers invaluable resources to the scientific community.. The growth of this community is expected to continue in upcoming years. The size and diversity of the gamer community show that video games are a universal entertainment activity that transcends generations, gender and cultures, and one of the most remarkable applications of this media is the development of citizen science games that engage participants in the analysis of real scientific data. Introduced with. In the last decade, CSGs had a dramatic impact on the practice of citizen science, lowering the barrier to entry of scientific activities and bringing hundreds of thousands of new participants into the community. However, successful implementation of this concept also comes with its own challenges, such as reaching potential participants and maintaining player engagement The classical approach to design CSGs relies on gamification—that is, the introduction of game design elements that facilitate the acquisition of the expertise needed to complete the activity and increase engagement. The design of these CSGs is strongly rooted in the canonical presentation of the scientific task, which may hinder its entertainment value and, therefore, participation of the general public. Hence, their target audience focuses on users with prior interest in scienceTo answer to the challenge of user acquisition and engagement in citizen science, in 2015, Massively Multiplayer Online Science proposed to embed citizen science activities into commercial video games played by massive established gamer communities, relying on the leadership of game designers to ensure a seamless integration of the citizen science activity in the host video game user experience. The first incarnation of this concept washas a user base with a welcoming stance toward scientific narratives, and it had not yet been shown that citizen science can work in any type of video game, specifically gamer communities not familiar with scientific narratives. In the present work, we reinforce the primacy of game design to overcome the challenges of integration of citizen science in commercial games. We also leverage our previous experience withto develop a CSG for microbiome data analysis that follows ‘game-first design’ principles. This approach aims to create a pure game that integrates scientific computation mechanisms in its core gameplay rather than adapting existing scientific research modus operandi . Eventually, this methodology can lead to fundamental alterations in the canonical presentation of the data that will prevent the complexity of the scientific task from obfuscating the accessibility or altering the user experience. We found that this approach of redesigning the original task with a fresh ‘untrained’ eye can bring valuable improvements from these other disciplines of game or narrative design. This approach results in massive gains in public participation without sacrificing the relevance of the collected answers. More importantly, it provides access to new human computation resources capable of executing complex computational tasks on large scientific datasets, which would otherwise be unfeasible with classical CSGs.is designed to improve a reference multiple alignment of 1 million 16S ribosomal RNA sequences from The Microsetta Initiative’s American Gut Project gameplay. Players are tasked with aligning the colored bricks, representing nucleobases, to the guides on the left, by inserting yellow gap bricks. They receive a bonus for full rows and must reach the par score to progress to the next puzzle. Inpipeline from data collection to alignment output, in particular how data flow from the initial alignment of 1 million sequences to the analysis results featured in this paper. Thedemonstrates that commercial video games can provide massive human processing resources for the manual curation and analysis of large-scale genomic datasets that could not be completed otherwise.The data featured in this article come from a set of 953,000 rRNA fragments sequenced from stool samples submitted by participants in the AGP), the player sees 7–20 sequences of 4–10 nucleotides. Each sequence is displayed as a vertical pile of bricks, each color representing a nucleotide . The bricks are collapsed , and the player is asked to insert a finite number of gaps to improve a score determined by the number of bricks correctly aligned to the guides. These targets, located on the left, display the most common nucleotides in the corresponding alignment column. By inserting gap tokens, the player is using their natural knack for pattern matching to realign a region of the scaffold alignment. The limited number of tokens, set by a naive greedy artificial intelligence player based on how easily it could improve the alignment, forces the player to make tough choices. This greedy player also sets a target score that the player must beat to progress to the next puzzle, enforcing a minimal effort. During the first year of the initiative, we collected approximately 75 million puzzle solutions . The solutions were used as ‘votes’ by players on potential errors in the scaffold alignment, and a corrected alignment was generated. Here we report results for ouralignment and benchmark alignments produced by several state-of-the-art de novo multiple alignment programs as well as an alignment produced by a greedy algorithm . The whiskers are located 1.5 times the IQR from the ends of the box. The dots outside the whiskers are the outliers. Note: one outlier point for the right-most distribution, pyNAST, with a value of 124, is not shown on the plot but is considered in the statistics shown., Compound distance to the reference Greengenes tree. That compound metric was obtained as a scaled average of the Kendall–Colijn and Triplet distance. More detail is provided inA central objective of improving alignments of microbial genomic sequences was to better understand their phylogeny. To assess whether this goal was achieved, we inferred phylogenetic trees from our alignments with FastTree. Greengenes has been previously benchmarked for fragment insertion, and SEPP with Greengenes has been shown to outperform de novo phylogeny inference, when a high-quality tree and alignment are already availableWe also formulated the hypothesis that improved alignments would lead to some improvement in the separation of taxa associated with different behaviors, profiles and diseases. To confirm this, we measured effect sizes on UniFracdistances over 74 non-technical variables available in the AGP metadata associated with the samples used for sequencing. These variables relate to the host’s lifestyle, health condition, food or general profile.. The top five variables with highest delta are, respectively, teeth brushing frequency, diabetes, number of types of plants, antibiotic history and alcohol frequency.We backed up this analysis by assessing whether the effect sizes obtained were significantly different than what could be observed in a random assignment of categories to samples. We annotated Fig.values associated with the null hypothesis that our results are compatible with a random outcome. We observed an enrichment of significant outcomes in the variables with high effect sizes and, in particular, 13 variables for whichachieves a higher significance category than SEPP, whereas the opposite occurs 10 times, generally on variables with lower effect sizes. These improvements observed on most variables confirm that the previously reported improvements to phylogeny can be perceived in meta-analyses. Although overall improvement over SEPP is limited as SEPP still outperformsdoes outperform SEPP, and the two approaches lead to distinct solutions that are complementary in improving understanding of gut microbe phylogeny and its impact on human health, thus satisfying criterionAs stated previously, the structure is an important component of a high-quality MSA of a strongly structured RNA region. Given that thealignment contains about 99% of bacterial sequences, it is possible to map its columns to the bases of the state-of-the-art structural model of the 16S bacterial rRNA defined on the Comparative RNA Web To estimate the quality of such mapping, we report the proportion of non-gap nucleotides that cannot be mapped to the structure , the most common response that we received was enthusiasm and curiosity about science. Although quantifying this attitude would be its own study and, thus, left for future work, our experience in this project leads us to think that player engagement was driven by a combination of game-first design and genuine interest in science from the public. Moreover, beyond the optimization of the tradeoff described above, the inherent benefits of participating in a citizen science initiative, such as improvements in science literacy and increased connectedness of the public to the scientific world, further justifies the exploration of the extra gamification region of that tradeoff: reaching more participants is a valid objective in its own right . Along with presenting more stimulating gameplay, these guide offsets allow the user to correct potential errors in the scaffold alignments at a larger scale. As a result, they are more noisy than regular puzzles were removed, and a final set of 9,667 cluster representative sequences was obtained, which accounts for 946,740 sequences of the initial dataset.mini game, the player sees 7–20 sequences of 4–10 nucleotides . Each sequence is displayed as a vertical pile of bricks, each color representing a random base. The bricks are collapsed , and the player is then asked to insert a finite number of gaps to improve a score determined by the number of bricks correctly aligned to the guides. These targets, located on the left, display the most common nucleotides in the corresponding alignment column. By inserting gap tokens, the player is using their natural knack for pattern matching to realign a region of the scaffold alignment. The limited number of tokens, set by a naive greedy AI player based on how easily it could improve the alignment, forces the player to make tough choices. This greedy player also sets a par score that the player must beat to progress to the next puzzle, enforcing a minimal effort. The game is displayed in Fig.Puzzles were added to the game on a regular basis. The results presented in this paper use the solutions of the first 1.4 million puzzles , submitted to the players between April 2020 and July 2021. To get a wide enough distribution of solutions, each puzzle was released in three different versions, each with a slightly different number of gap tokens available. Each different version was aimed to be played by about 15 players, for a total of 45 per puzzle. For each alignment region , sequences are sampled from the PASTA alignment. To compensate for the bias that comes from the vertical orientation, puzzles are built both from left to right and from right to left. Additionally, each sequence in each puzzle has a small probability to be shortened or elongated to show puzzle sequences of different lengths, allowing the player to simulate deletions. Finally, an offset was sometimes introduced between the guides and the puzzle sequences. An offset of 1 would mean that puzzles using sequences from the alignment columns 10–14 would have the guides from columns 9–13, to enhance the user’s action space; they would then have to push up many bricks just to get back to the initial PASTA configuration. Through these variations in the puzzles, the players are given opportunities to re-evaluate alignment decisions made by the PASTA algorithm.Puzzles are discarded if they offer little incentive to move bricks because the starting gravity effect already yields a local optimum. This led to some alignment regions being overrepresented in the puzzles due to a higher acceptance rate, which we interpreted as these regions presenting more room for improvement via puzzles. For each puzzle, the 20–60 user solutions were filtered by their similarity to the distribution of gap positions from all submitted solutions to that puzzle. The player solutions were filtered using two criteria: how far from optimality the solution was and how far from the player consensus the solution was. The distance from optimality in was defined as the score difference against the solution with the highest score using the same number of gaps for that puzzle. The player consensus in was defined as the centroid of the distribution of solutions. Solutions that were too far from this combined objective were excluded, and the exclusion threshold was set to exclude about two-thirds of the solutions, to keep a subset that was most representative of the ensemble of high-quality player solutions. This threshold was selected experimentally based on visual exploration of rejected solutions: we selected a threshold for which no obvious outliers were included, and all excluded solutions were clear outliers.The puzzle solutions are converted to positional sequence annotations, which are normalized to account for variance in coverage, and unannotated positions are filled with PASTA and/or Rfam version 14 , it is difficult to fairly compare them as alignments. Thus, the validation process for our methods is centered around the comparison of phylogenetic trees estimated from the alignment with FastTree 2.1 . Pairwise effect sizes were then calculated with Evident version 0.4.0 . We reproduced these experiments with shuffled metadata to assess significance. We also examined two technical variables—the sample plates and the liquid handling robot—and observed no significant change. It should be noted that the aggregation of player solutions and the production of an alignment were not optimized for performance on effect sizes. This choice aims to avoid overfitting by training to optimize for a phenotype, due to the relatively small size of those data. Furthermore, it was established in previous work that there is a relationship between the quality of the tree and the observed phenotype . Thus, alignments were optimized on tree metrics, and effect sizes were kept as an independent evaluation. As expected from previous work, thegame. It was fully optional. No participants were recruited, and potential participants were informed of how and why the data would be used through a presentation video played before gameplay. Only gameplay data were collected. No identifying or personal information about the participants was collected, and participants were fully anonymous to the research team.). These data include all the puzzles that players solved, all the solutions submitted by the players and related data, such as the order in which they made their moves to solve the puzzle. The players are identified by unique alphanumeric strings as it was not possible to obtain their informed consent to share their personal information, as these data were collected through a video game.All the code used to generate data, process data and compute results presented in this paper is freely available as a GitLab repository linked on the project website:Nebel, S., Schneider, S. & Rey, G. D. Mining learning and crafting scientific experiments: a literature review on the use of Minecraft in education and research.Santos, D., Zagalo, N. & Morais, C. Players perception of the chemistry in the video game No Man’s Sky.Cheng, M. T. et al. The use of serious games in science education: a review of selected empirical research from 2002 to 2013.Stegman, M. Immune Attack players perform better on a test of cellular immunology and self confidence than their classmates who play a control video game.Google Scholar 103–110 .Google ScholarDress, A. W. M., Huber, K. T. & Steel, M. ‘Lassoing’ a phylogenetic tree I: basic properties, shellings, and covers.Hori, N., Denesyuk, N. A. & Thirumalai, D. Shape changes and cooperativity in the folding of the central domain of the 16S ribosomal RNA.Li, W., Ma, B. & Shapiro, B. A. Binding interactions between the core central domain of 16S rRNA and the ribosomal protein S15 determined by molecular dynamics simulations.Yang, B., Wang, Y. & Qian, P.-Y. Sensitivity and correlation of hypervariable regions in 16S rRNA genes in phylogenetic analysis.Spiers, H. J., Coutrot, A. & Hornberger, M. Explaining world‐wide variation in navigation ability from millions of people: citizen science project Sea Hero Quest.Needleman, S. B. & Wunsch, C. D. A general method applicable to the search for similarities in the amino acid sequence of two proteins.Estaki, M. et al. QIIME 2 enables comprehensive end-to-end analysis of diverse microbiome data and comparative studies with publicly available data.players, whom we are unfortunately not able to credit individually but without whom this project could not have happened. We also thank Z. Bányai, a former principal collaborator of Massively Multiplayer Online Science , who contributed to the early development of MMOS. We consider allplayers to be essential contributors to this publication, but it is not possibe to name them individually, which is why they are included as a group in the author lists. This work was supported by a Genome Canada and Génome Québec grant to J.W., A.Sz., M.B. and S.C. R.K. is partially supported by a Director’s Pioneer Award from the National Institute of Health .Roman Sarrazin-Gendron, Parham Ghasemloo Gheidari, Alexander Butyaev, Timothy Keding, Eddie Cai, Jiayue Zheng, Renata Mutalova, Julien Mounthanyvong, Yuxue Zhu, Elena Nazarova, Chrisostomos Drogaris, Mathieu Blanchette, Attila Szantner & Jérôme WaldispühlDavid Bélanger, Michael Bouffard, Mathieu Falaise, Vincent Fiset, Steven Hebert, Jonathan Huot, Jonathan Moreau-Genest, Ludger Saintélien, Amélie Brouillette, Gabriel Richard & Sébastien CaisseJoshua Davidson, Dan Hewitt, Seung Kim, David Najjab, Steve Prince & Randy PitchfordR.S.-G. contributed to the design of the game, designed the puzzles used in the game and designed and wrote the alpha version of the code related to the puzzle generation pipeline, the solution processing and analysis pipeline and the initial versions of the solution filtering and alignment improvement pipelines. R.S.-G. also designed and implemented the validation process and computed most of the results, authored most of the figures and wrote most of the paper. P.G.G. designed and implemented much of the final version of the alignment improvement pipeline. A.B. designed and implemented much of the database systems, managed the data and hardware systems and prepared the data release. T.K. contributed to the puzzle generation and alignment improvement pipelines and improved the implementation of much of the project codebase. E.C. designed and implemented much of the final version of the solution filtering pipeline. J.Z., R.M., J.M., Y.Z., E.N. and C.D. are the other members of the scientific team who contributed to the design and/or the implementation of specific scripts and figures. This group performed this work under the supervision of J.W. and M.B. at the School of Computer Science at McGill University. M.B. contributed to the analysis of the results and reviewed the paper. J.W. contributed to the design of the game and methods, analysis of the results, writing of the manuscript and the acquisition of funding. Thedevelopment team. The game design was performed as a team under the supervision of G.R. The overall development and integration ofwas coordinated by A.B., under the leadership of S.C. and R.P. Data collection and sequencing were performed by The Microsetta Initiative, led by D.M. and R.K. They contributed to the scientific aspects of the project on aspects related to data, phylogeny, effect size computations and validation and reviewed the paper. A.Sz. presented the initial idea of theconcept and contributed to the writing of the paper. A.Sz. and K.E. designed, developed and maintain the technological framework connecting the scientific and game development teams.J.W. is supported by a Genome Canada grant , which is co-funded by Gearbox Studio Québec, Inc., and Massively Multiplayer Online Science . J.W. is an occasional scientific consultant for Takeda pharmaceuticals, for which he receives income. The agreement has been reviewed and approved by McGill University in accordance with its conflict of interest policies. A.Sz. is the CEO and founder of MMOS, a Swiss innovator company that presented the initial idea and set up the first major collaborations between citizen science and video games and provides the underlying technological services to connect these two entities. MMOS received operating fees from Gearbox Studio Québec, Inc. S.C. is co-studio head at Gearbox Studio Québec, Inc., which develops the gameis sold as a premium game. R.K. is a scientific advisory board member and consultant for BiomeSense, Inc., has equity and receives income. He is a scientific advisory board member and has equity in GenCirq. He is a consultant and scientific advisory board member for DayTwo and receives income. He has equity in and acts as a consultant for Cybele. He is a co-founder of Biota, Inc., and has equity. He is a cofounder of Micronoma and has equity and is a scientific advisory board member. D.M. is a consultant for, and has equity in, BiomeSense, Inc. The terms of these arrangements have been reviewed and approved by the University of California, San Diego, in accordance with its conflict of interest policies.thanks Paul Gardner, Firas Khatib and the other, anonymous, reviewer for their contribution to the peer review of this work.This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit
United States Latest News, United States Headlines
Similar News:You can also read news stories similar to this one that we have collected from other news sources.
 Improving Comfort and Battery Life with VR Headstrap Battery StrapEvery hardcore VR user knows there are two important things when it comes to daily VR gaming: comfort, and battery. One accessory that can improve both of those things is a headstrap that houses a built-in mobile battery, or a “battery strap”. Let’s face it, the stock strap that comes with the Quest 3 is a complete joke. It almost offends me that Meta raises their prices every year and continues to find materials from the dollar store to make their stock strap. Thus, users have no option but to buy a new one, and Meta bets on that. That’s why they keep doing it and they make it simple to plug and play new straps into the headset; . When it comes to VR accessories, I’ve reviewed almost every major thing on the market
Improving Comfort and Battery Life with VR Headstrap Battery StrapEvery hardcore VR user knows there are two important things when it comes to daily VR gaming: comfort, and battery. One accessory that can improve both of those things is a headstrap that houses a built-in mobile battery, or a “battery strap”. Let’s face it, the stock strap that comes with the Quest 3 is a complete joke. It almost offends me that Meta raises their prices every year and continues to find materials from the dollar store to make their stock strap. Thus, users have no option but to buy a new one, and Meta bets on that. That’s why they keep doing it and they make it simple to plug and play new straps into the headset; . When it comes to VR accessories, I’ve reviewed almost every major thing on the market
Read more »
 The Wicked Movie Is Already Improving On The Musical In 1 Magical WayAngel Shaw is a Core Features Senior Writer with Screen Rant who knows far too much about the worlds of Harry Potter and the Lord of the Rings.
The Wicked Movie Is Already Improving On The Musical In 1 Magical WayAngel Shaw is a Core Features Senior Writer with Screen Rant who knows far too much about the worlds of Harry Potter and the Lord of the Rings.
Read more »
 American Horror Story: Delicate Part 2 Is Already Improving On Part 1It was necessary.
American Horror Story: Delicate Part 2 Is Already Improving On Part 1It was necessary.
Read more »
 Republican lawmaker says federal government has a role to play in improving access to healthcareCongresswoman Beth Van Duyne recently held a field hearing in Denton, Texas.
Republican lawmaker says federal government has a role to play in improving access to healthcareCongresswoman Beth Van Duyne recently held a field hearing in Denton, Texas.
Read more »
 How Winemakers Are Reducing Carbon Emissions While Improving FlavorIn Paso Robles, a collection of winemakers are practicing sustainable farming not just because it's good for the environment, b/c it makes better wine
How Winemakers Are Reducing Carbon Emissions While Improving FlavorIn Paso Robles, a collection of winemakers are practicing sustainable farming not just because it's good for the environment, b/c it makes better wine
Read more »
 Border czar Harris touts ‘improving’ lives in Central America with Guatemalan presidentThe meeting with Guatemalan President Bernardo Arevalo was part of Vice President Kamala Harris's effort to address the 'root causes' of migration.
Border czar Harris touts ‘improving’ lives in Central America with Guatemalan presidentThe meeting with Guatemalan President Bernardo Arevalo was part of Vice President Kamala Harris's effort to address the 'root causes' of migration.
Read more »